
March 10, 2026 Vishnu Subramanian14 min read
Vishnu Subramanian14 min read
How We Made GPU Instance Launch 4x Faster
From 8 seconds to 1.8 — how we tore apart every layer of our instance creation pipeline in three days to make GPU launches feel instant.
Vishnu SubramanianFrom 8 seconds to 1.8 — how we tore apart every layer of our instance creation pipeline in three days to make GPU launches feel instant.
Vishnu Subramanian
How much does an NVIDIA A100 GPU cost? $7K-$15K to buy, from $1.49/hr to rent. Compare A100 cloud pricing, specs & benchmarks across providers. Updated March 2026.
Vishnu Subramanian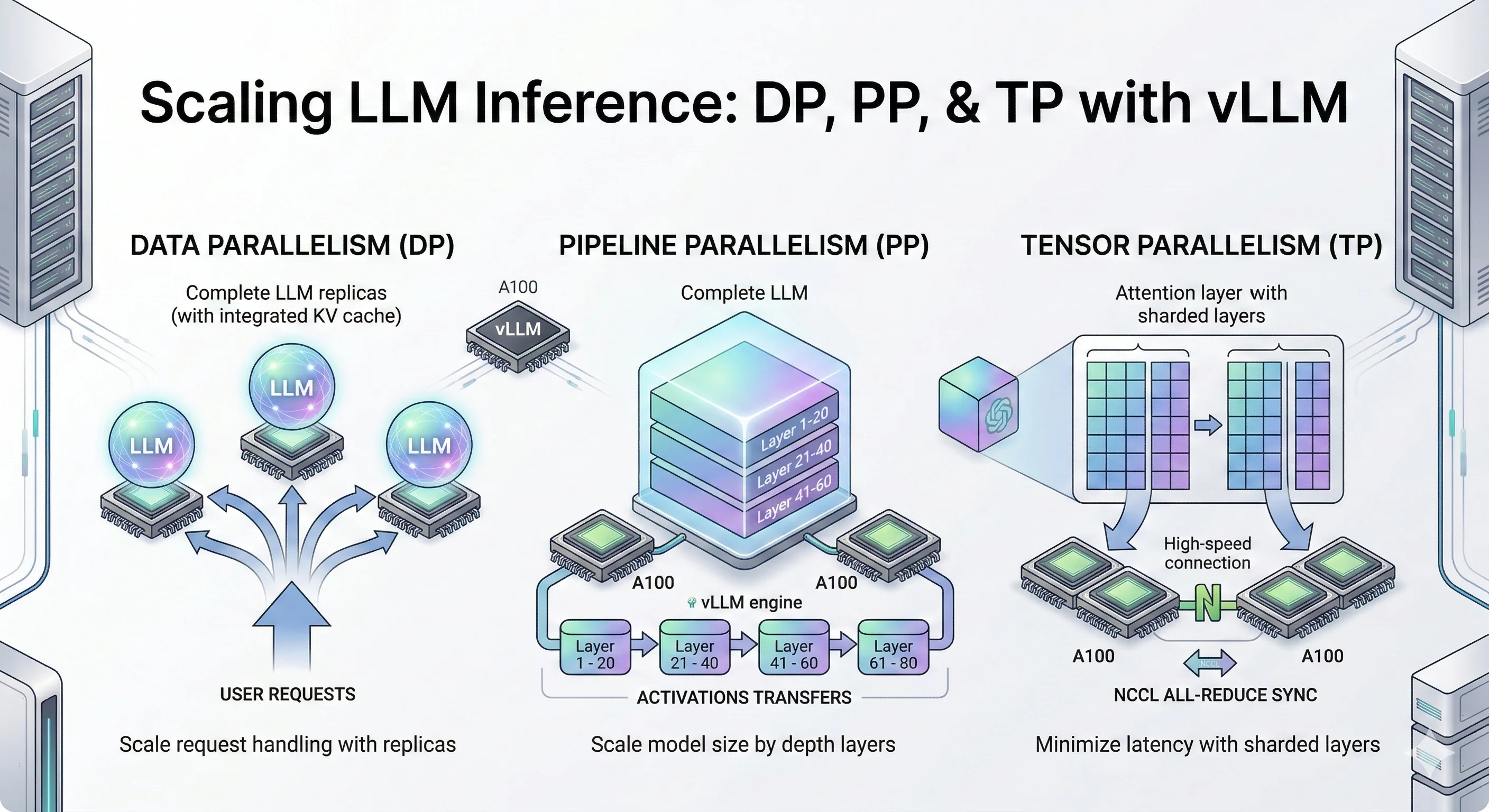
Learn how to scale LLM inference using data parallelism, pipeline parallelism, and tensor parallelism in vLLM. Practical guide with A100 GPU benchmarks comparing DP vs PP vs TP.
 Jaydev Tonde
Jaydev Tonde
NVIDIA L4 GPU costs $2K-$3K to buy or from $0.44/hr to rent. Complete L4 specs, benchmarks, and cloud pricing comparison. The best budget GPU for AI inference in 2026.
Vishnu Subramanian
NVIDIA L4 vs A100 compared: specs, inference benchmarks, pricing, and when to choose each GPU. L4 is 2x cheaper per token. A100 wins on VRAM and training.
Vishnu Subramanian
Learn 5 practical vLLM optimization methods: prefix caching, FP8 KV-cache, CPU offloading, disaggregated prefill/decode, and zero-reload sleep mode, with benchmark-backed guidance.
Jaydev Tonde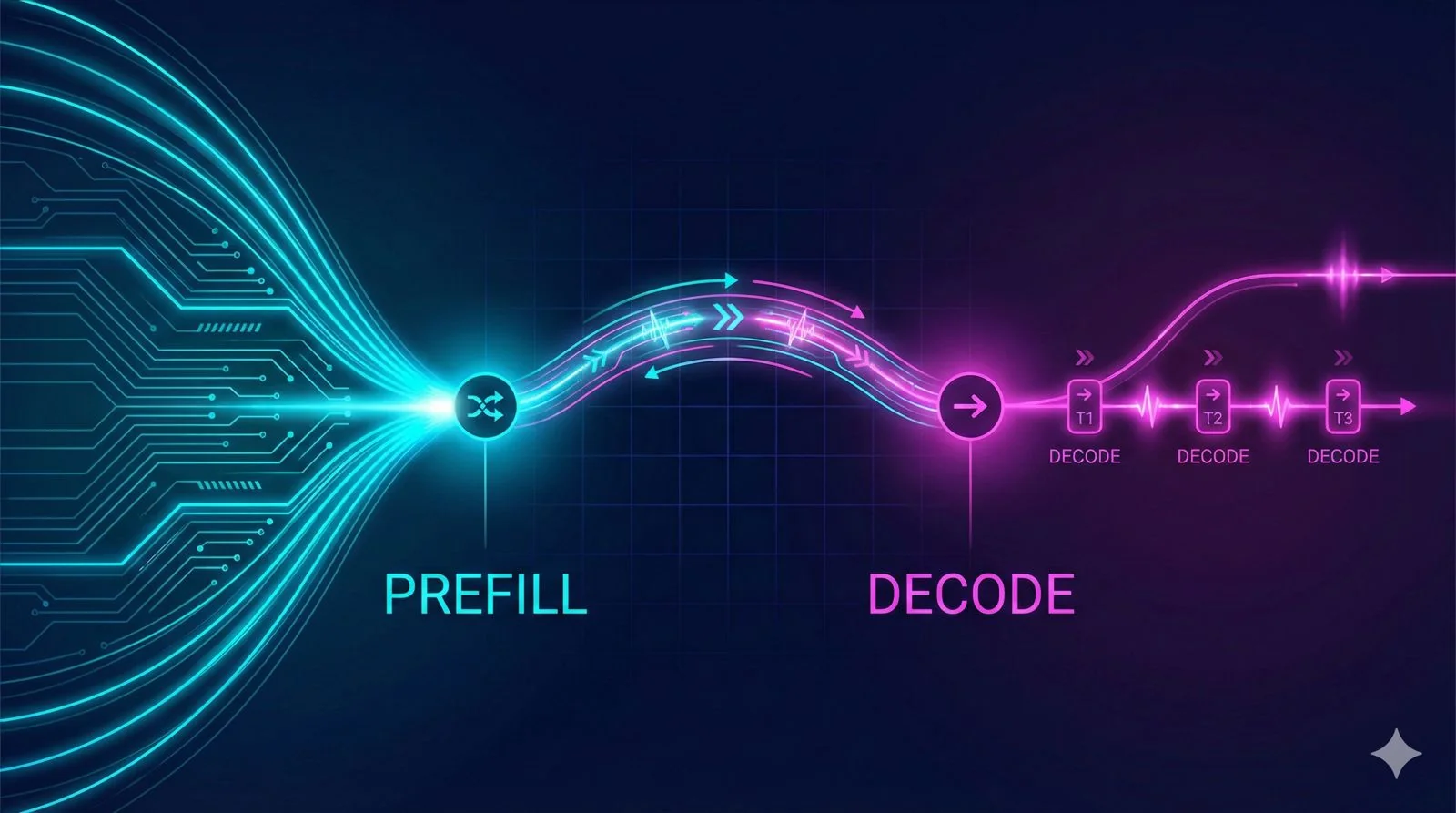
Part 1 of my LLM optimization research series. Exploring how Meta's disaggregated prefill-decode strategy separates prompt processing from token generation - and what it means for JarvisLabs.
Vishnu Subramanian
NVIDIA H100 price starts at $25,000 to buy or $2.99/hour to rent. Compare H100 cloud GPU pricing from Jarvislabs, Lambda Labs, RunPod & more. Updated January 2026.

NVIDIA H200 GPU costs $30K-$40K to buy or $3.80/hr to rent. Compare H200 cloud pricing from AWS, Azure, Google Cloud & Jarvislabs. Updated January 2026.
Vishnu Subramanian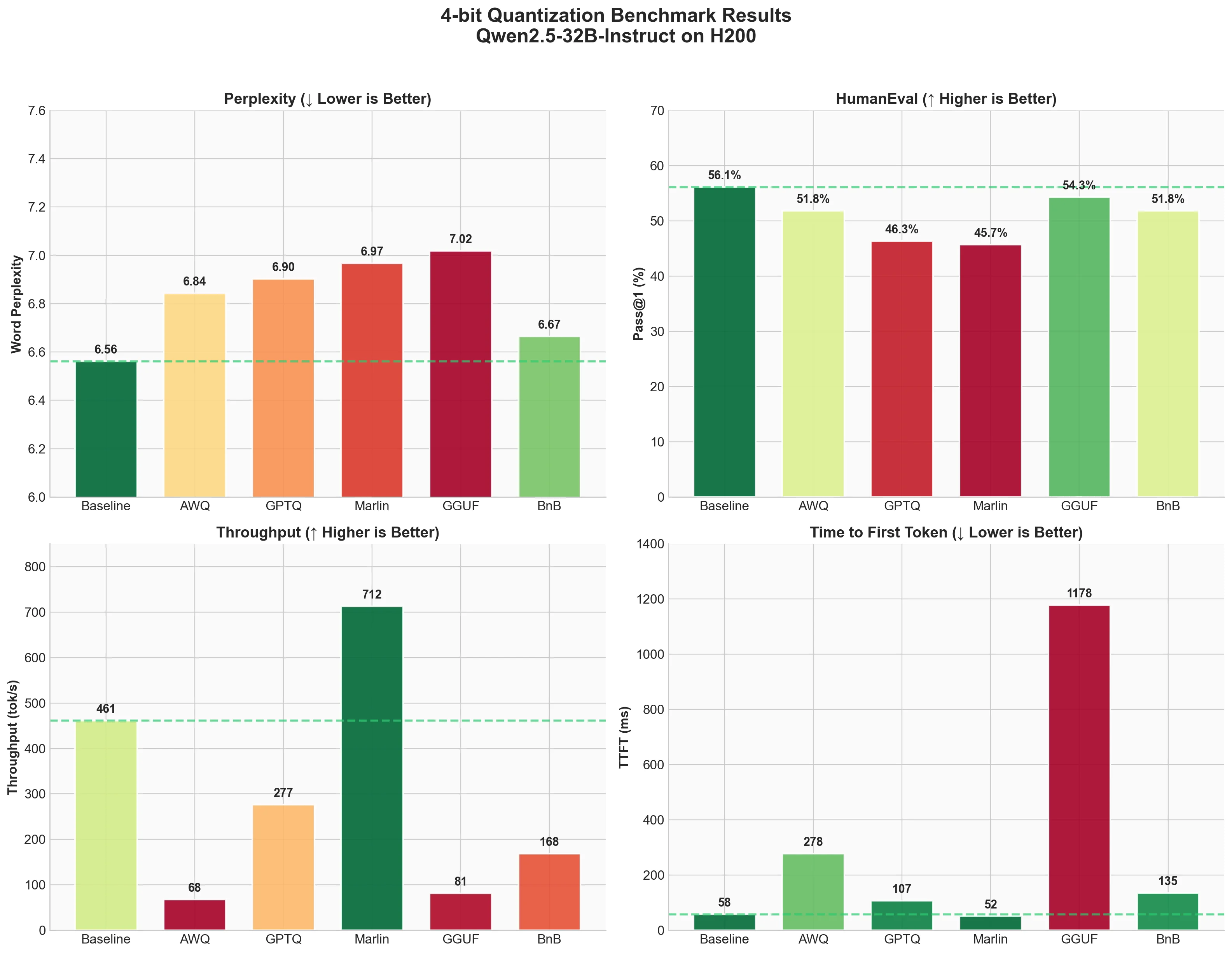
Complete guide to LLM quantization with vLLM. Compare AWQ, GPTQ, Marlin, GGUF, and BitsandBytes with real benchmarks on Qwen2.5-32B using H200 GPU - 4-bit quantization tested for perplexity, HumanEval accuracy, and inference speed.
Jaydev Tonde
Learn how to deploy MiniMax M2.1 with vLLM for agentic workloads and coding assistants. Covers hardware requirements, tensor/expert parallelism, benchmarking on InstructCoder, tool calling with interleaved thinking, and integration with Claude Code, Cline, and Cursor.
 Atharva Ingle
Atharva Ingle
Learn how to speed up LLM inference by 1.4-1.6x using speculative decoding in vLLM. This guide covers Draft Models, N-Gram Matching, Suffix Decoding, MLP Speculators, and EAGLE-3 with real benchmarks on Llama-3.1-8B and Llama-3.3-70B.
Jaydev TondeConfused by NVIDIA H100 price in India? Complete 2025 pricing guide: purchase (₹25-30L) vs rent (₹242/hr). Plus hidden costs nobody talks about.
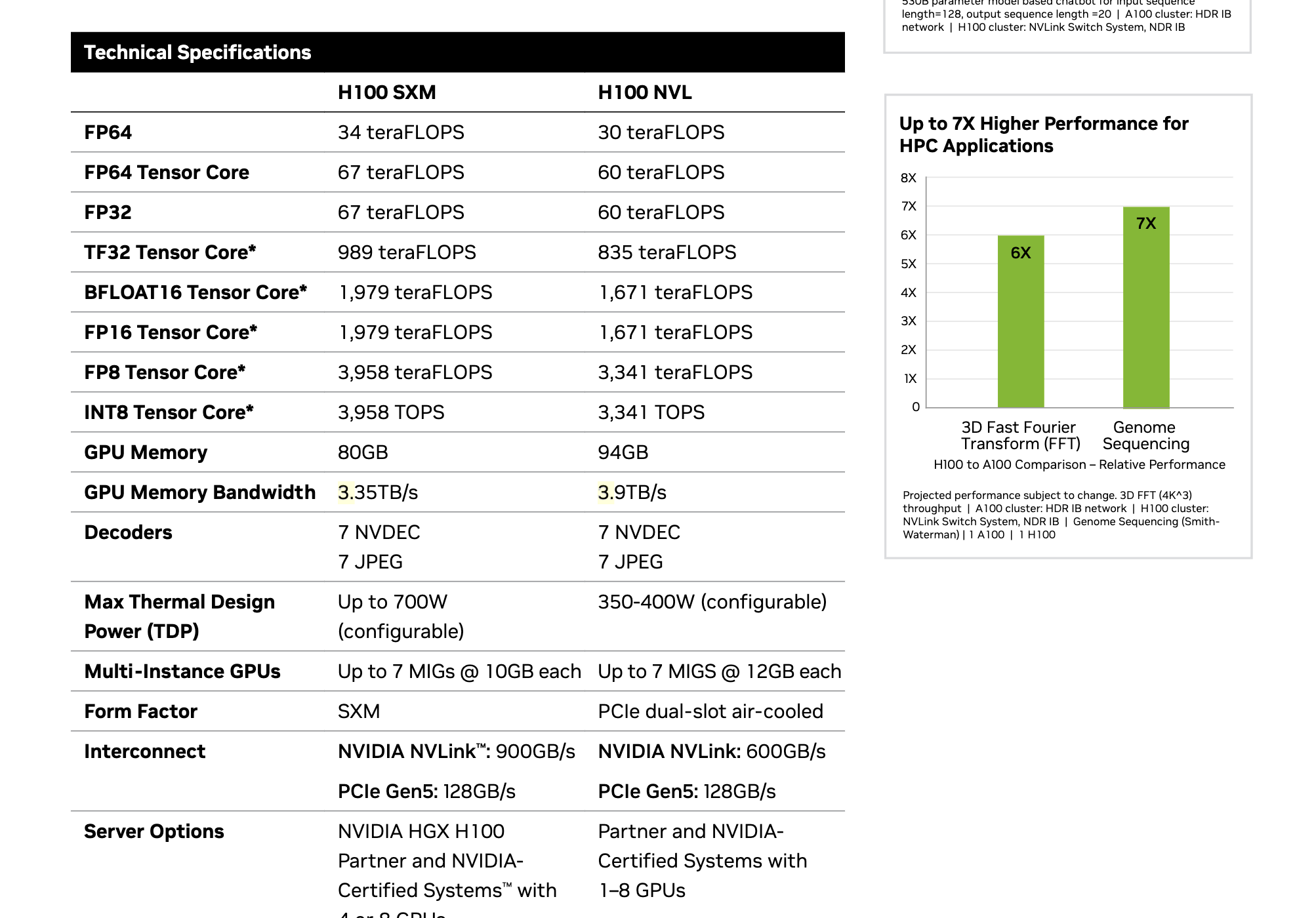
A deep dive into CUDA cores, Tensor Cores, precision modes, and other specialized GPU features that impact performance.

H100 vs A100 GPU comparison: specs, benchmarks, pricing & which to choose. H100 is 2-3x faster, A100 is 40-60% cheaper. Updated February 2026 with latest cloud pricing.
Vishnu Subramanian
Learn how to improve your Stable Diffusion prompts using Ollama and LLMs in ComfyUI. Step-by-step guide to setup, workflow, and best practices for enhanced AI image generation.
Learn how to effectively track and manage ML experiments using Weights & Biases (W&B) and Hydra. A comprehensive guide for machine learning practitioners and researchers.
Atharva Ingle
Step-by-step guide to set up and run FLUX.1 Schnell for AI image generation using ComfyUI on cloud GPUs. Includes workflows, LoRA integration, and practical examples.
Explore uncensored LLM models, their differences from ChatGPT, and how they're built. Learn about foundation models, fine-tuning, and running unfiltered AI models locally.
Vishnu Subramanian
Step-by-step guide to install and run Flux.1 AI image generator on cloud GPU. Learn how to generate high-quality AI images using Flux's open-source model with detailed setup instructions and examples.
Vishnu Subramanian
Step-by-step guide to creating custom AI training datasets using Fooocus's face swap and pose matching features for Stable Diffusion model finetuning

Learn how to effectively deploy and interact with Ollama LLM models using terminal commands, local clients, and REST APIs. Discover tips for choosing the right GPU, managing storage, and troubleshooting common issues.
Vishnu Subramanian
Discover how to enhance your PyTorch scripts using Hugging Face Accelerate for efficient multi-GPU and mixed precision training. Learn setup, configuration, and code adaptation for faster deep learning model training.
Vishnu Subramanian
Learn how to train large language models efficiently using DeepSpeed and HuggingFace Trainer. This step-by-step guide shows you how to optimize GPU memory and train 10B+ parameter models on a single GPU using ZeRO-Offload.

Learn how to build a toxic comment classifier using RoBERTa and PyTorch Lightning. This step-by-step tutorial covers mixed precision training, multi-GPU setup, and Weights & Biases integration for ML model tracking.

Learn how to boost ResNet-50 accuracy from 75.3% to 80.4% using advanced training techniques, including BCE loss, data augmentation, and optimization strategies. A comprehensive guide to modern CNN training best practices.
Vishnu Subramanian