CUDA Cores Explained
Choosing the right GPU can feel daunting if you don't understand what's under the hood. Today’s graphics processing units are far more than just “graphics” cards. They’re sophisticated, multi-faceted compute platforms designed to excel at a wide array of tasks—from rendering lifelike imagery in real time to training massive AI models in record time.
In this post, we’ll break down the different core types inside modern NVIDIA GPUs, explain various precision modes, and show you how to choose the right configuration for your specific workloads—whether you’re researching AI, running a data center, developing HPC applications, or all three.
Core Types in Modern GPUs
Modern NVIDIA GPUs feature multiple core types and precision options. The image below, referencing the NVIDIA H100 architecture, demonstrates the range of formats (FP64, FP32, TF32, BFLOAT16, FP16, FP8, and INT8) and configurations (e.g., H100 SXM, H100 NVL) that GPUs can support. Each format and core type is optimized for different tasks, allowing a single GPU to excel at everything from double-precision simulations to mixed-precision AI training.
Key Highlights:
- FP64 Tensor Core FLOPS: Critical for scientific and engineering tasks that demand high numerical accuracy.
- FP8 Tensor Core FLOPS: Designed for AI, allowing models to train and infer more quickly with reduced precision.
- Multi-Instance GPU (MIG): Enables secure, efficient partitioning of GPU resources across multiple users or tasks.
By leveraging specialized cores and selecting the appropriate precision mode, you can tailor GPU performance to your exact needs like large-scale language model training, HPC simulations, or multi-tenant data center deployments.
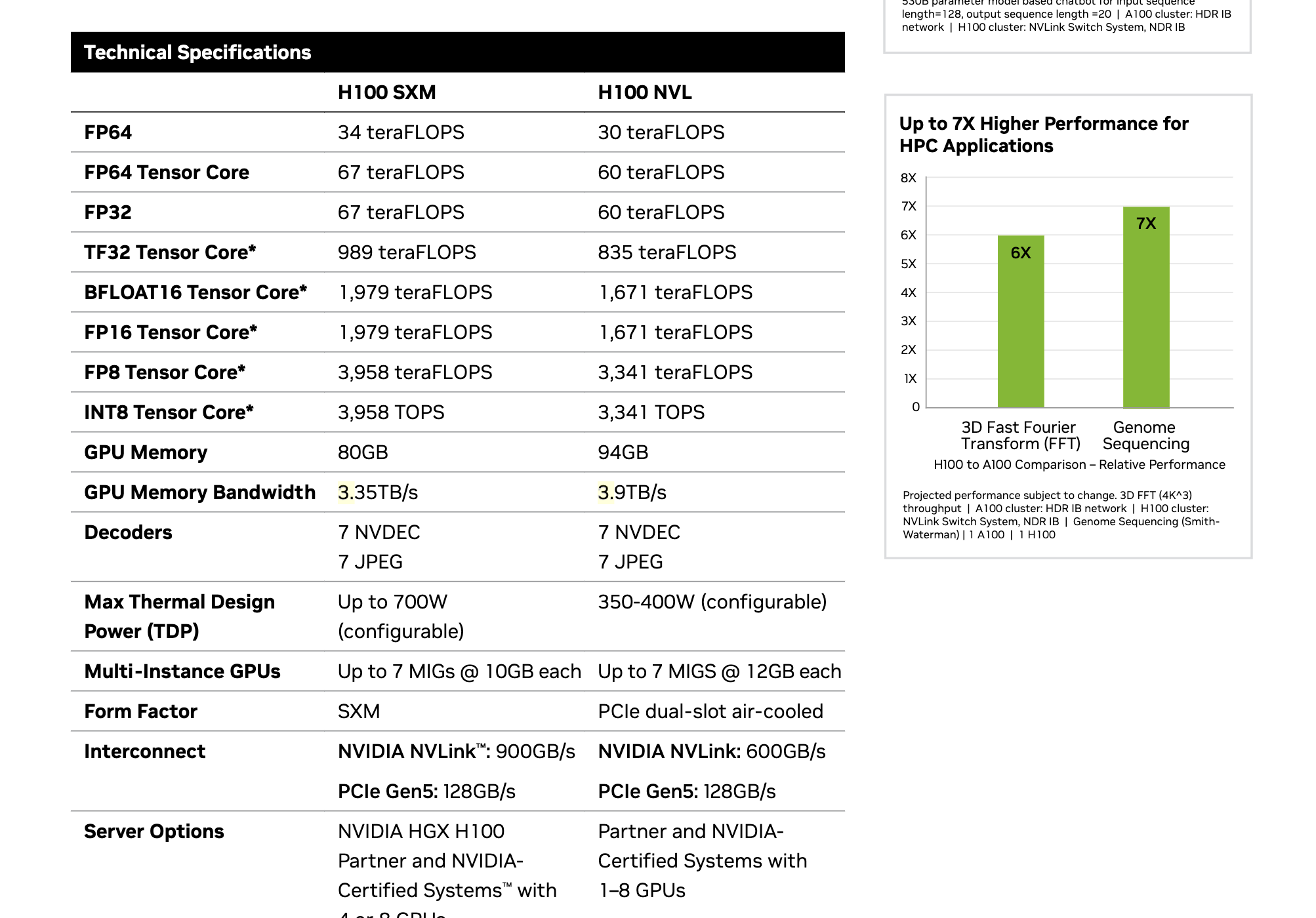
Image source: NVIDIA H100 Technical Specifications
A Quick Comparison of Core Types
| Core Type | Primary Use Case | Supported Precision Modes | Example Workloads |
|---|---|---|---|
| CUDA Cores | General parallel computing | Typically FP32, FP64 | Graphics rendering, general HPC tasks, basic AI |
| Tensor Cores | AI & HPC acceleration | FP64 to FP8 (mixed-precision) | Deep learning training, HPC simulations |
| RT Cores | Real-time ray tracing in graphics | N/A (Specialized for RT tasks) | Gaming, photorealistic rendering |
Ready to start building?
Get a GPU instance running in 90 seconds. JupyterLab, VS Code, or SSH. Per-minute billing so you only pay for what you use.
Try Jarvislabs FreeCUDA Cores: The Parallel Workhorses
What They Are:
CUDA cores are the fundamental parallel processors in NVIDIA GPUs. They excel at handling large numbers of identical, simple calculations simultaneously, making them great for graphics rendering, particle simulations, and certain HPC workloads.
Key Benefits:
- Scalable Parallelism: The more CUDA cores you have, the more computations you can run in parallel—up to the limit of memory and bandwidth.
- Breadth of Applications: From gaming to basic deep learning tasks, CUDA cores form the baseline compute capability for a wide range of workloads.
Tensor Cores: Accelerators for AI and HPC
What They Are:
Tensor Cores are specialized units optimized for matrix multiplications, a core operation in AI and HPC. They handle mixed-precision arithmetic—formats like FP16, BF16, TF32, and FP8—enabling massive speedups without significantly impacting model accuracy.
Why They Matter:
- AI Training: Deep learning tasks like training large language models (e.g., GPT-4) can see training times cut dramatically by leveraging Tensor Cores.
- High-Performance Computing (HPC): Tensor Cores also support FP64 for scientific simulations, bringing acceleration to computational fluid dynamics, weather forecasting, and more.
Precision Options:
- TF32 (Tensor Float 32): Balances accuracy and performance for AI training without complicated hyper-parameter tuning.
- BF16, FP16, FP8: Faster computations with slightly reduced precision. Ideal for large-scale AI models where throughput outweighs perfect accuracy.
Ray Tracing (RT) Cores: Realistic Lighting in Real-Time
While the H100 focuses on data center and HPC/AI tasks, many NVIDIA GPUs include RT Cores to accelerate ray tracing, enabling realistic lighting, reflections, and shadows in real time. Although primarily relevant to gaming and visualization, RT Cores highlight how GPUs have evolved into specialized toolkits capable of powering advanced rendering.
Ready to start building?
Get a GPU instance running in 90 seconds. JupyterLab, VS Code, or SSH. Per-minute billing so you only pay for what you use.
Try Jarvislabs FreeOther Specialized Hardware Features
MIG (Multi-Instance GPU):
MIG allows a single data center GPU to be partitioned into multiple isolated instances, each with dedicated memory and compute. This feature is crucial in shared environments, like cloud platforms, ensuring secure, efficient, and cost-effective utilization of expensive GPU resources.
Dynamic Programming (DPX) Instructions:
For certain HPC and AI workloads—such as genome sequencing, route optimization, or graph analytics—GPUs like the H100 offer DPX instructions to accelerate dynamic programming algorithms, improving performance for tasks once considered CPU-bound.
Choosing the Right Precision Mode
Modern GPUs handle a variety of numeric formats, each balancing speed and accuracy:
- FP64 (Double Precision): Essential for HPC workloads that require exacting accuracy (e.g., climate modeling, molecular simulations).
- FP32 (Single Precision): Common default for many HPC and graphics tasks.
- TF32: Introduced for AI training to balance speed and model accuracy without extensive tuning.
- BF16 and FP16: Half-precision formats that drastically speed up AI training and inference. Ideal for training large models where perfect numerical precision is less critical.
- FP8: A cutting-edge format (Hopper architecture) pushing performance even further in massive language model training.
How to Choose:
- If accuracy is paramount (e.g., scientific simulations): Use FP64.
- If you’re training large AI models: Consider FP16, BF16, or FP8 to accelerate training times significantly.
- If you’re balancing accuracy and speed for AI: TF32 is a strong choice.
Real-World Applications
AI Training and Inference:
- Large Language Models: Training GPT-style models benefits tremendously from Tensor Cores and lower-precision formats (FP16, FP8).
- Recommendation Systems & Vision: Process massive image datasets or user interactions quickly, driving insights faster.
High-Performance Computing (HPC):
- Scientific Simulations: Leverage FP64 Tensor Cores to speed up workloads like molecular modeling or fluid dynamics.
- Dynamic Programming Algorithms: Accelerate tasks like genome sequencing or complex routing challenges with DPX instructions.
Enterprise Multi-Tenancy and Cloud Services:
- MIG Partitions: Assign separate GPU instances to different teams or customers, ensuring secure, right-sized resources and improving ROI in large-scale data centers.
Using the NVIDIA H100 as a Reference
The NVIDIA H100 Tensor Core GPU exemplifies how these technologies come together:
- Huge Performance Leap: Tensor Cores and advanced precisions enable faster AI training compared to previous generations.
- Flexible Precision Support: From FP64 to FP8, letting one GPU handle both HPC-level accuracy and lightning-fast AI computations.
- MIG and Confidential Computing: Ensure secure, efficient multi-tenant deployments.
While the H100 is a pinnacle of current GPU architecture, the principles—specialized cores, flexible precision, multi-instance support—are widely applicable across modern GPU product lines.
Practical Tips and Next Steps
- Profiling and Tuning: Tools like NVIDIA Nsight Systems or TensorBoard can help you identify bottlenecks and tune precision settings for optimal performance.
- Benchmarking and Experimentation: Start with recommended precision modes for your application and experiment. For example, if training times are too long, try switching from FP32 to FP16.
- Further Reading:
- NVIDIA H100 Technical Specifications
- NVIDIA’s Mixed-Precision Training Guide for best practices in AI workflows.
Key Takeaways
- CUDA Cores: General-purpose parallel processors suitable for a broad range of tasks.
- Tensor Cores: Specialized for matrix-heavy AI and HPC workloads, offering massive speedups at various precision levels.
- Precision Modes: Fine-tune performance by choosing formats like FP64 for accuracy or FP16/FP8 for speed in AI training.
- Advanced Features (MIG, DPX): Enable multi-tenant environments and accelerate specific workloads like dynamic programming.
- Adaptability: Modern GPUs are highly versatile compute platforms—not just for graphics—capable of accelerating everything from next-gen AI models to exascale HPC simulations.
By understanding these building blocks—CUDA Cores, Tensor Cores, precision modes, and more—you can better leverage modern GPUs for your projects, whether you’re scaling up AI training, running intricate scientific simulations, or optimizing resource sharing in a data center.
Want to see how multiple GPUs work together for LLM inference? Read our guide on scaling LLM inference with data, pipeline, and tensor parallelism in vLLM — it covers how tensor parallelism splits matrix operations across GPUs and why inter-GPU communication bandwidth (NVLink vs PCIe) matters.
Ready to start building?
Get a GPU instance running in 90 seconds. JupyterLab, VS Code, or SSH. Per-minute billing so you only pay for what you use.
Try Jarvislabs Free